I've spent most of my career running procurement processes — at Gleeds, CBRE, Turner & Townsend. I've built scoring frameworks, chaired evaluation panels, and signed off on contractor recommendations worth hundreds of millions. I believed, as most practitioners do, that a well-structured panel of experienced assessors was the closest thing to an objective evaluation.
Earlier this year, running live parallel evaluations alongside three major real estate developers on Vision 2030 programmes in Saudi Arabia, I found data that made me question that assumption directly.
We ran the same tenders through TruBuild simultaneously with each client's own manual process — same criteria, same weightings, blind to each other's scores. Then we compared.
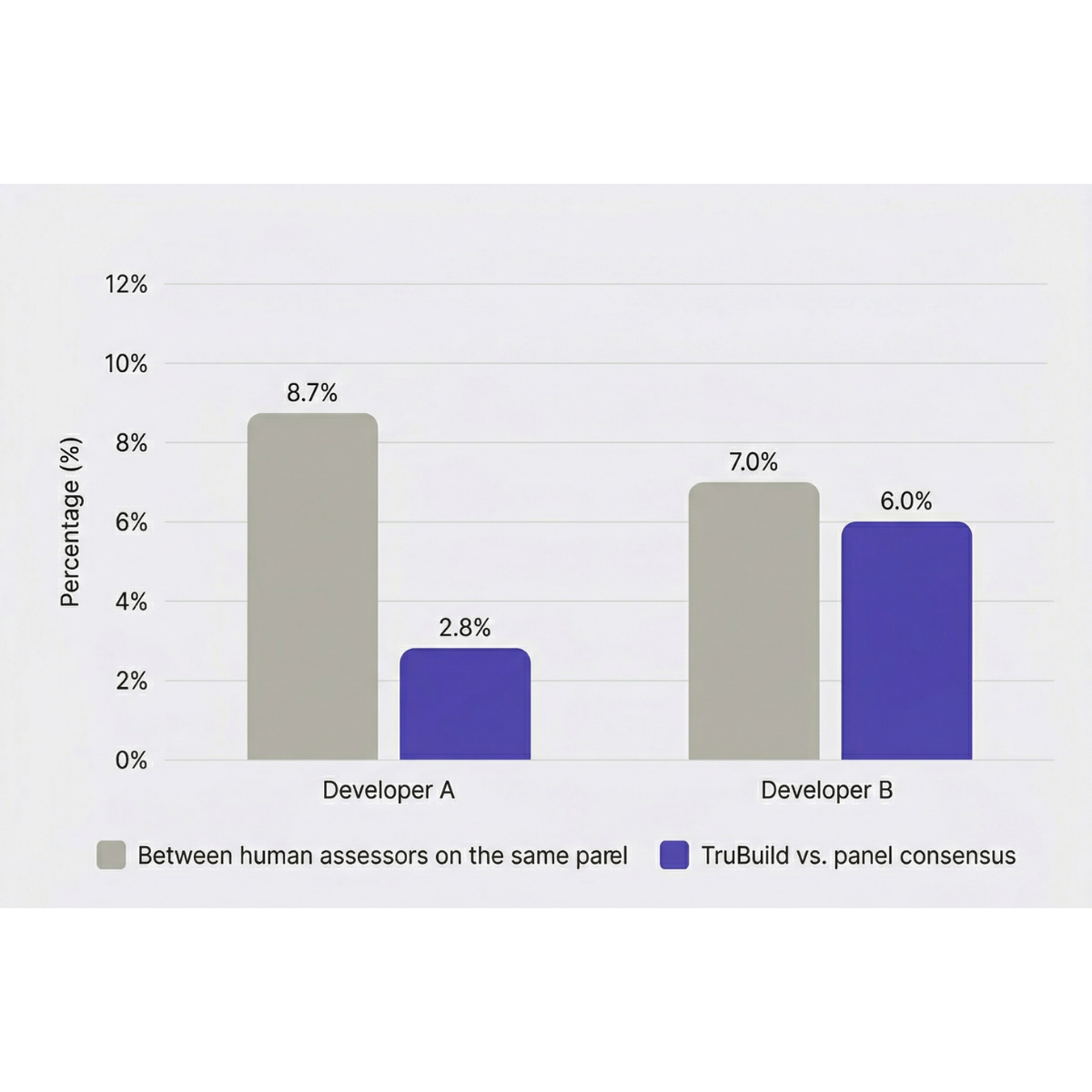
The finding that stopped me wasn't the efficiency gap, though that was significant. Across two of the three evaluations, the average scoring variance between human assessors on the same panel was 7–8.7%. In those same evaluations, TruBuild's deviation from the panel's collective consensus was 2.8% and 6% respectively. In both cases, TruBuild was more consistent than the human assessors were with each other.
That consistency finding matters most when you look at what's underneath it — the specific scoring decisions driving the variance.
In one evaluation, a single criterion produced this result across three assessors on the same panel: 0, 0, and 4 out of 5. No written comments explained the discrepancy. The scores were averaged, the ranking was produced, and the process moved forward. Nobody flagged it.
This wasn't isolated. A pattern that emerged across the evaluations: high scores rarely came with written justification. Low scores occasionally did — briefly. The result is an evaluation record where the most consequential decisions are the least documented.
There's a second finding I didn't expect. In one evaluation, a contractor produced a disorganised submission — relevant information buried across misnamed files. Manual assessors, working under time pressure and relying on PDF searches, missed content that was demonstrably there. TruBuild found it regardless of where it sat in the document structure. The contractor's actual capability was assessed. The presentation penalty disappeared.
This cuts both ways: a well-presented weak bid can outscore a disorganised strong one, and nobody on the panel necessarily knows that's happening.
The time and cost numbers varied across the three pilots but were consistent in direction. Two evaluations ran against a four-week manual process costing $31,800 — TruBuild completed both in two hours for $3,500. The third ran against a three-week process costing $21,800 — same two-hour result from TruBuild, at $2,200. Across all three, total evaluation time including report creation dropped from three to four weeks down to four days.
But efficiency isn't the point I'm making. The organisations we work with aren't primarily trying to save money on evaluation. They're running programmes where a challenged procurement decision doesn't just delay a contract — it delays a project, triggers a legal process, and puts careers on the line.
The question I keep returning to is not whether AI should support evaluation. It's whether unexplained scoring variance between assessors on the same panel — with no audit trail — is actually acceptable in an environment where every decision must be defensible. Having sat inside these processes for most of my professional life, I think the honest answer is no.
TruBuild is running pilot evaluations with project owners and consultancies across the GCC and UK. If you're running a complex tender and want to see how your evaluation compares, try the demo.